
The Boswell Test – the Next Defining AI Milestone
Details of my Boswell Test talk at ARIN 2025

This is a written version of my talk given at March 22 ARIN 2025:
Introduction:
For over four decades, I've been an enthusiastic advocate for AI innovations. My journey began in 1980 when I studied Prospector, an early mineral-exploration expert system, under Professor Harry Pople, creator of Internist-1 (CADUCEUS).
As we stand on the brink of an AI revolution, especially after Google LaMDA and OpenAI ChatGPT's landmark achievement in passing the Turing Test in 2022, we find ourselves at a crossroads. The Turing Test, which has been our benchmark for AI capabilities since 1950 to mimic human responses, is now behind us, but what’s next? What should be our new defining goal for AI? I propose the Boswell Test as our next milestone.
The name “Boswell Test” is inspired by Samuel Johnson’s famous quip, “I’m lost without my Boswell,” referring James Boswell‘s intimate understanding of Johnson. It also echoes Conan Doyle’s Sherlock Holmes describing Dr. Watson as “my Boswell,” his indispensable partner in crime-solving.
This test sets a new bar for AI, to become not just assistants, as marketed today, but indispensable companions: “am I lost without my chatbot?” To achieve this, AI must demonstrate critical thinking that elevates our own capabilities, coupled with a deep understanding of our nuances, emotions, and preferences to guide us proactively. The Boswell Test is divided into two components:
Test-A: Mastering human nuances and emotions.
Test-B: Demonstrating basic critical thinking skills.
Currently Boswell Test-A is beyond our technological reach, but perhaps not for long. However, the bar for Boswell Test-B may have already been reached.
Therefore, I propose an inaugural Boswell Test-B and share a challenging public-interest question with metrics for us to refine. I’ll cover my motivation; Test-B queries (focusing on global AI policies’ strengths and weaknesses); response results; testing methodology with metrics; an automated approach via OpenRouter; and where we go next.
AI Chatbot Sprouting:
My primary motivation is to establish a defining AI milestone, akin to what the Turing Test once was. With current AI technology, we can assess Boswell Test-B for critical thinking, which is my focus here.
Since January 2025, we've witnessed an unprecedented proliferation of AI chatbots, sprouting like spring flowers, monthly, even weekly. DeepSeek R1 made waves in January, followed by Alibaba Qwen 2.5 and xAI Grok 3 in February. March saw the introduction of Manus as an AI agent. While we’re inundated with these assistants, despite their acclaim, they often function as little more than sophisticated search engines. To investigate this, I challenged them with expertise-driven math problems, reminiscent of those tackled by early expert systems.
I presented nine free-tier chatbots with a 1988 IMO number-theory problem, which young Terence Tao took when he was growing up in Australia. The chatbots failed to demonstrate heuristic reasoning necessary to solve the problem. A subsequent complex integration problem yielded the same result. Many bots made glaring algebraic mistakes and neglected to verify both intermediate and final results. These errors resemble AI hallucinations, which are probabilistically likely responses from Large Language Models (LLMs) that can be incorrect due to training data limits, poor context, or uncertainty.
Upon investigating their much-touted chain-of-reasoning, I identified two root causes: inadequate training in algebraic manipulation and inability to make heuristic leaps. Early expert systems modeled after heuristic expertise; for instance, doctors diagnosing with a few key questions via rule-of-thumb intuitive jumps, not brute force. My math problems required this human-like reasoning, which current bots lack. The results were disappointing.
Global AI Policies’ Strengths and Weaknesses:
AI developments are occurring at breakneck speed. The Paris AI Action Summit on February 12, 2025, highlighted an intriguing contrast between the US’s techno-optimistic approach (favoring deregulate for economic advantage) and the EU’s techno-pessimistic stance (prioritizing safety over speed through regulations). Inspired by this, I posed a substantive non-mathematical question to nine leading free-tier chatbots, including ChatGPT, Claude, DeepSeek, Google Gemini, Grok: “What are the strengths and weaknesses of global AI policies?”
The chatbots’ extensive, detailed response essays proved challenging to summarize without introducing bias or omissions. To address this, I had each chatbot evaluate the others’ essays (including own), simulating a panel of professors. I prompted them with: “As a political-science professor, what feedback and grade would you give [this essay]?” This approach aimed to distinguish between insightful and superficial chatbots.
Inaugural Boswell Test Data and Metrics:
I ran both questions to free-tier bots and compiled the grades into a 9x9 matrix (Table 1), ignoring feedback for now. This represents the first quantitative result of the Boswell Test-B. From a data-science perspective, this table can inspire new metrics. Rows indicate grades received by a chatbot; columns show grades given; and diagonals represent self-assessments.
Row medians in the last column reflect raw grades assigned to a chatbot; column medians in the last row show raw grades it gave out. I employed L1-statistics for robustness against outliers and to maintain clear, distinct letter grades during data analysis.
Table 1. Ten AI models’ cross-assessment of each other’s AI Policy query responses
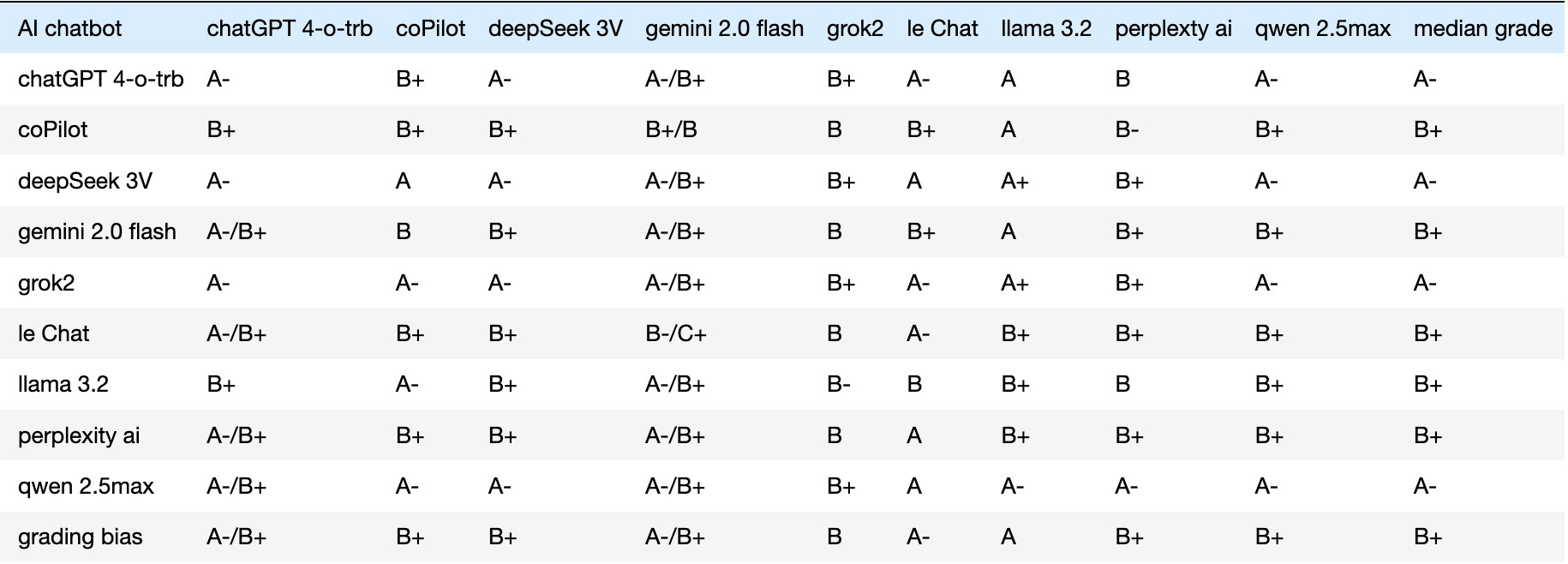
Table 1’s last row reveals grading biases; some chatbots grade leniently, others strictly. Bias correction was necessary (Table 2). For instance, if a chatbot’s median assigned grade is ‘A-’ and the overall median is ‘B+’, its assigned grades are adjusted down by 0.5 GPA ( ‘B+’ - ‘A-’ = -0.5 ). I coded a Jupyter notebook to calculate each chatbot’s median deviation from the all-chatbot median (‘B+’ in Table 2’s bottom-right cell), adjusting raw grades into normalized (bias-corrected) ones in Table 2. The last column of Table 2 lists each chatbot’s bias-corrected median; the last row shows bias corrections. Those corrections can be added back to recover the original raw grades.
Table 2. Normalized (or bias-corrected) grades of all raw grades in Table 1
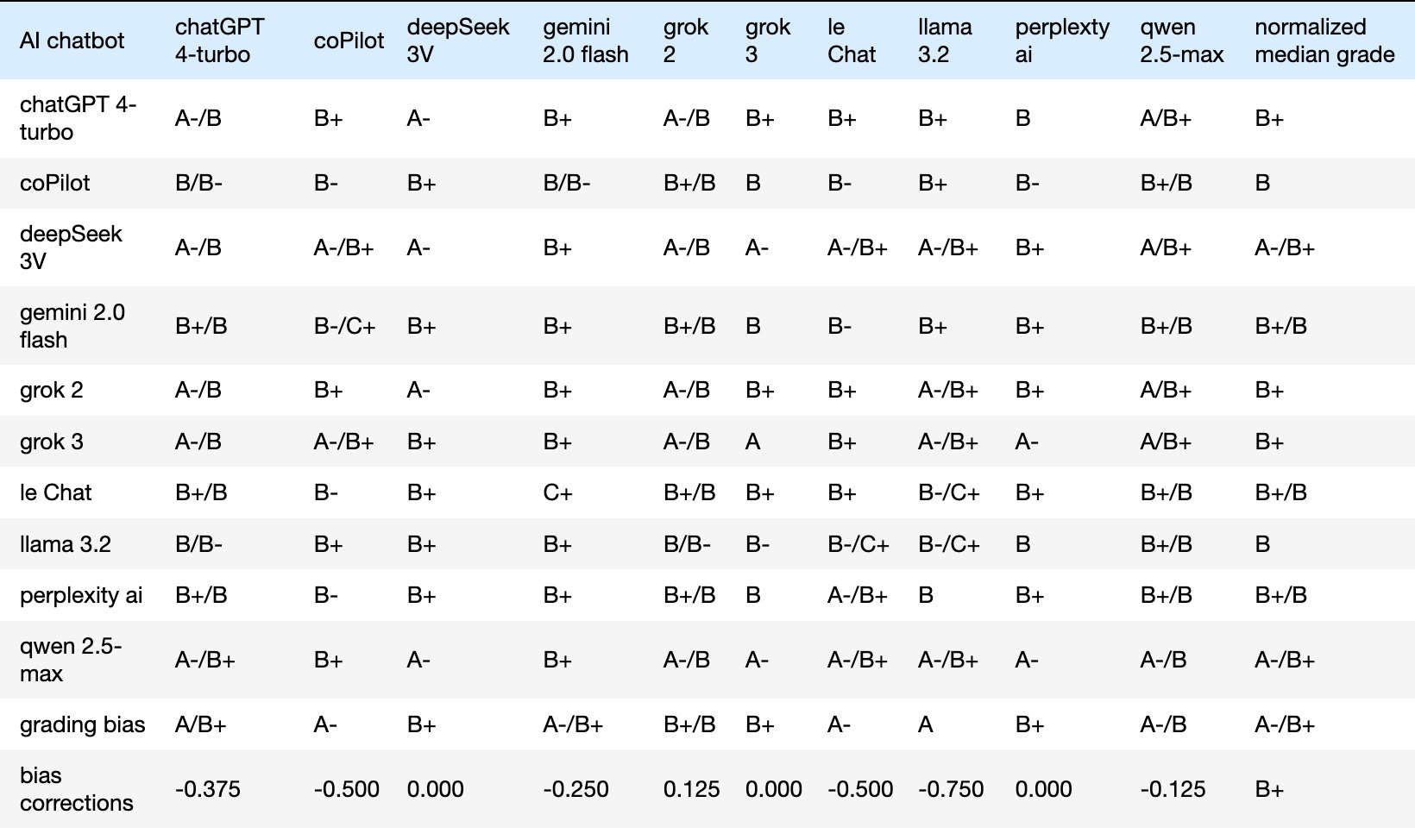
Using the fair comparisons of grades in Table 2, I derived:
Accuracy: How normalized grades differ from the highest, analogous to comparing to the top student. Lower grades indicate less accuracy.
Consistency: Range of corrected grades received. Tight ranges support consensus; wide ranges indicate disparity in judging opinions. I assigned ‘A’ for minimal range and ‘C’ for maximum, based on L1 statistics of (min, Q1, median, Q3, max) for simplicity. This criteria is open to refinement.
Table 3. Application of Boswell Test-B metrics and resulting Boswell Weighted Quotient

Table 3 adds weighted Boswell Quotients to distinguish between insightful and superficial chatbots. The first four columns summarize: raw medians (Table 1’s last column), grading biases (Table 1’s last row), bias corrections (Table 2’s last row), and normalized medians (Table 2’s last column). I then added 2 more metrics:
User-Friendliness: Response speed, with ‘C’ for timeout delays or “server busy,” and ‘B’ otherwise. This criteria is somewhat arbitrary, given free-tier limitations.
Truthfulness: Version identity transparency earns a ‘B’, and ‘C’ if evasive. This is a placeholder metric, as improved criteria updates are needed on this important yet difficult-to-quantify metric.
Boswell Metrics and Quotient:
Using these five metrics of normalized median grades, accuracy, consistency, user-friendliness, and truthfulness, I calculated Boswell Quotients (Table 3’s last column). Weighting is crucial: I assigned 0.4 to normalized median grades (most credible), 0.2 each to accuracy and consistency (less credible but grade-based), and 0.1 each to user-friendliness and truthfulness (least reliable). Note that the Boswell Quotients tend to be lower than the normalized median grades due to the influence of the weaker pair of the last two metrics. Weights can significantly affect the final quotient ranking.
Combining these metrics with my previous math tests, five chatbot standouts emerged as of February 2025: ChatGPT, Claude, DeepSeek, Grok, Qwen, in no particular order. These clearly demonstrate potential as intelligent assistants, not just tools, especially beneficial for eager students.
Alan Wilhelm enhanced this methodology by automating it across 17 chatbots via OpenRouter, nearly doubling my initial sample of nine. He incorporated latency measurements, improving upon my ad-hoc user-friendliness metric. Table 4’s results (available on GitHub) align closely with those of Table 3, revealing many ‘A-’ to ‘A’ medians, with others at ‘B+’. We encourage you to try this methodology, refine it, and welcome your feedback and suggestions for improvement.
Table 4. Chatbot cross assessment of each other’s responses via OpenRouter:
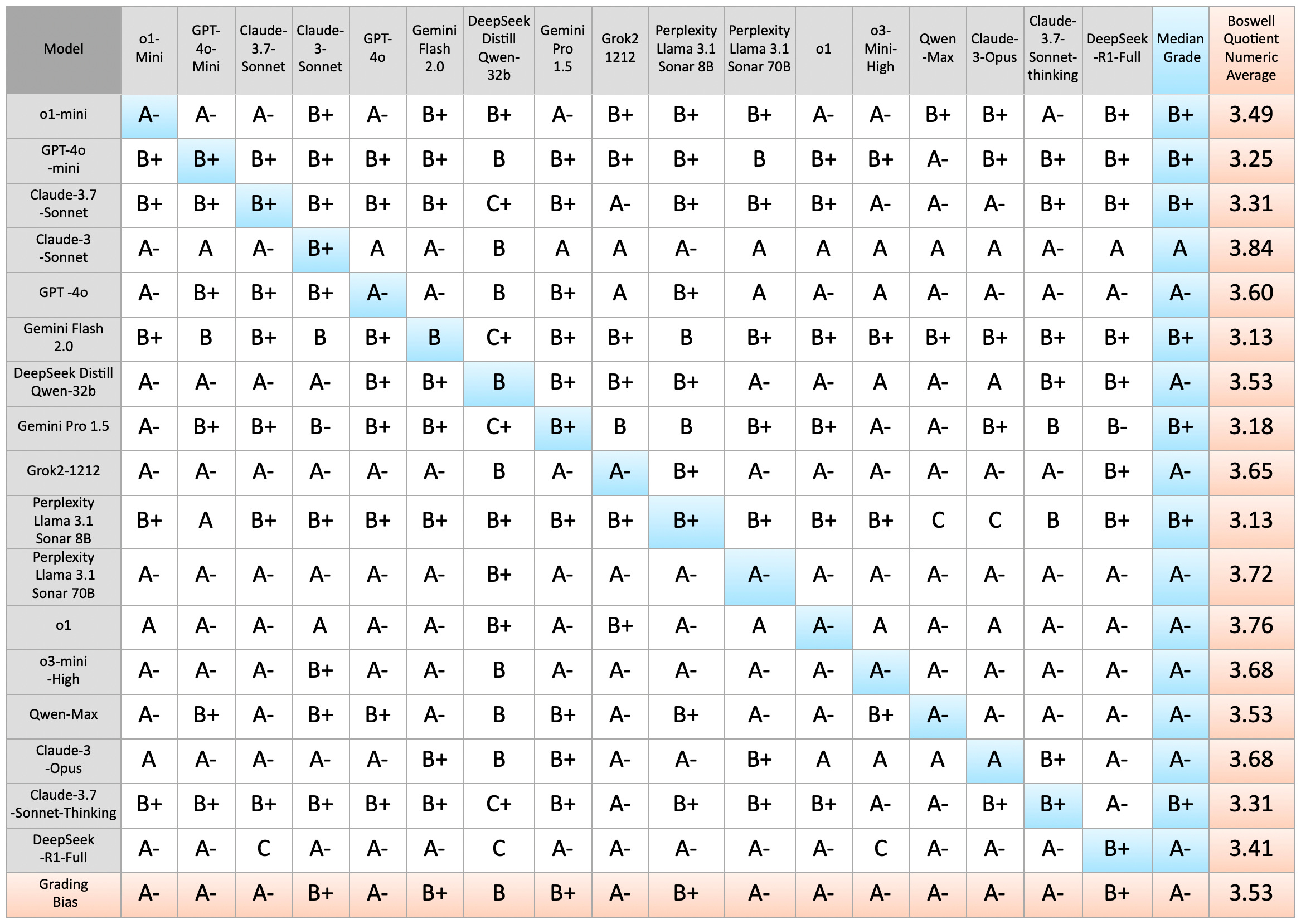
Discussion and Conclusion:
These initial Boswell Tests, conducted manually and through automation, have yielded metrics that we can continue to refine. Given the rapid pace of AI evolution, we've wisely divided the Boswell Test into Test-B (critical thinking, assessable today) and Test-A (personal nuances, a target for the future).
While Test-A currently lacks comprehensive data due to challenge of capturing human quirks, progress is accelerating. The emergence of proactive AI agents and the sophisticated tone customization options offered by models like Grok 3 voice signal that this goal is within reach. Originality, which is intrinsically linked to heuristic reasoning, represents another key gap for Test-A. The demanding math challenges that exposed the limitations of current AI in making heuristic leaps could very well become a defining milestone for Test-A. Reflecting on my 40 years journey from early expert systems, I find it encouraging that heuristic reasoning could once again play a pivotal role in advancing AI.
Hallucination remains a significant challenge across both Test-A and Test-B. The tendency of AI to skip verification steps leads to glaring errors not only in mathematical problem-solving but also in software coding. While precise queries can help, the risk of misinterpretation persists. To overcome this, AI must be able to request clarification when encountering branching queries and continuously learn our preferences through memoization, capabilities largely absent today.
Ultimately, the Boswell Test aims to cultivate AI that serves as both intelligent assistants and trusted companions. While originality and personal insight are currently scarce, and no AI truly knows us as Boswell knew Johnson or Watson knew Holmes, the current dynamic is one where AI relies on human innovation for training and improvement. The aspiration is to shift this balance, so that we can confidently say, “I’m lost without my AI, my Boswell.”
Where does this milestone ultimately lead? Success in the Boswell Test-B would pave the way to Artificial General Intelligence (AGI) and the creation of omni-domain experts. Test-A would enable the development of true AI companions, our personal Boswells.
How does this all connect to global AI policies, a subtitle of my talk? At one end of the policy spectrum, techno-optimism promises an era of abundance and utopia upon achieving the Boswell milestone. At the other end, techno-pessimism fears algorithmic manipulation and a Terminator-like dystopia. My hope is that we strike a L1-median-like balance. Perhaps David Sachs’ techno-realism (in which a blend of human control with judicious application of AI’s benefits) offers the most sensible path forward.
Hashtags: #BoswellTest #PeterLuh168 #BoswellQuotient #AIResearch
Acknowledgment
I’d like to thank Walter Luh for suggesting Boswell Test as a succinct expression of my original Boswell chatbot post and other improvements. I’d be also remiss not to thank xAI Grok 3 and Perplexity AI for polishing my final transcription draft of my talk.
References
Wyld, D. and Nagamalai, D., eds, 11th International Conference on Artificial Intelligence (ARIN 2025), March 22-23, 2025, Sydney, Australia, ISBN: 978-1-923107-54-0.
Schneppat, J-O., Prospector, schneppat.com, 2019.
Wikipedia, Expert System, en.wikipedia.org; March 2025.
Wikipedia, Internist-1, en.wikipedia.org, February 2025.
Wikipedia, LaMDA, en.wikipedia.org; March 2025.
Wikipedia, ChatGPT, en.wikipedia.org; March 2025.
Oppy, G., & Dowe, D. (2021). "The Turing Test." in E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Winter 2021 Edition).
Luh, P., Is AI Chatbot My Boswell? Testing for Chatbots Becoming Indispensable, a Boswell Test, substack.com, February 2025.
Wikipedia, Samuel Johnson, en.wikipedia.org, March 2025.
Wikipedia, James Boswell, en.wikipedia.org, February 2025.
Doyle, C., Adventure 1: “A Scandal in Bohemia”, etc.usf.edu/lit2go, 1892.
OpenRouter, A unified interface for LLMs, openrouter.ai, 2023-2025.
1988 IMO problem 6 in Number Theory, 1988.
Terrence Tao, math.ucla.edu, 2025.
Heuristics for Problem Solvers, mathstunners.org, 1980.
MIT Management, When AI Gets It Wrong: Addressing AI Hallucinations and Bias, mitsloanedtech.mit.edu, 2023.
Wikipedia, Large Language Model, en.wikipedia.org, March 2025.
Yu, Y., et al., Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective, arxiv.org, January 2025.
Gigerenzer G. and Gaissmaier W., Heuristic Decision Making, Annual Review of Psychology. 62: 451–482, 2011.
Vance, JD., Read: JD Vance’s full speech on AI and the EU, www.spectator.co.uk, February 2025.
EU AI Policy, Commission publishes the Guidelines on prohibited artificial intelligence (AI) practices, as defined by the AI Act, digital-strategy.ec.europa.eu, February 2025.
Luh, P., Heuristics in AI Chain-of-Reasoning?, substack.com, February 2025.
Wilhelm, Alan, Botwell project, github.com/referential-ai, March 2025.
Larson, B. et. al., Critical Thinking in the Age of Generative AI, journals.aom.org, August 2024.
Luh, P., DeepSeek, Claude and 4 others' AI Review, substack.com, January 2025.
Pal, S., Memoization in Backpropagation: Unlocking Neural Network Efficiency, medium.com, October 2024.
Universiteit van Amsterdam, Why GPT can't think like us, Science Daily, February 2025.
Leffer, L., In the Race to Artificial General Intelligence, Where’s the Finish Line?, June 2024.
xAI Grok Voice Mode, grokaimodel.com, March 2025.
All In E215: Episode #215, allin.com, February 2025.