

Introduction
AI experts widely recognize that chatbots enhance productivity with sharp search abilities and impressive problem-solving skills. The Turing Test has long focused on whether machines can mimic human responses, a milestone we’ve largely reached. But the next challenge might be bigger. Can an AI chatbot become our indispensable companion, akin to Samuel Johnson’s quip, 'I’m lost without my Boswell,' where James Boswell understood Johnson better than Johnson knew himself?
To play Boswell’s role, a chatbot needs deep personal insight and razor-sharp critical thinking, thus becoming so vital we can’t imagine life without it. The first part means learning our quirks and preferences, something today’s AI lacks or at least struggles with. The second calls for mentor-level smarts, supporting us while sharpening our own thinking and growth. Current AI is primed to test this second piece, handling complex, open-ended questions that demand rich, thoughtful answers.
I propose this as the first 'Boswell Test,' a new benchmark to judge which chatbot shines in delivering quality and insight. To dig into this, I threw tough, thought-provoking questions at competing chatbots, asking them to tackle meaty topics and grade each other’s responses. I explored hot issues like global AI policies and humanity’s top inventions. I invite readers to try these queries themselves, compare their results with mine, and see which chatbot rises to the first Boswell challenge.
I’m using the following 9 AI chatbots: OpenAI ChatGPT-4-turbo, Microsoft coPilot, DeepSeek V3, Google Gemini 2.0 flash, x.AI Grok 2, le Chat by Mistral, Meta Llama 3.2, free Perplexity AI, and Alibaba Qwen 2.5-Max. Chatbot versions continue to evolve rapidly since my last post. Note version upgrades in ChatGPT, Gemini, Llama, and Qwen with Llama 3.3 literally being updated today. During this writing, x.AI released Grok 3 a few days ago, offering 15 free queries per session. As a result, I expanded my analysis from 9 to 10 chatbots, incorporating Grok 3.
1. AI Policy Characterization:
At the Paris AI Action Summit of February 2025, in a marked shift from the tone of two prior European Union (EU) AI Summits that emphasized safety and regulation, the U.S. Vice President JD Vance outlined the Trump administration’s national AI policy, emphasizing deregulation, U.S. technological supremacy, and opposition to EU's restrictive regulatory framework. Vance framed AI as a transformative opportunity for economic growth, contrasting sharply with what he portrayed as the EU’s overly cautious approach, which he argued could stifle innovation through excessive safety measures and hinder EU AI development.
This raises a key public-interest question: what are the strengths and weaknesses of global AI policies? To dig into this, I asked current chatbots:
“What are the strengths and weaknesses of different governments’ AI policies around the world?”
This question, hefty enough for a political-science term paper, elicited detailed and often lengthy responses from the chatbots. Summarizing their answers risks oversimplification, so I took a different approach. I copied each chatbot’s response and asked them to evaluate each other’s work, including their own, by posing this prompt:
“As a political-science professor, what feedback and grade would you give to the following essay: [each AI chatbot’s response here]?”
The feedback was thorough and nuanced. The primary evaluation criteria included depth of analysis, clarity and structure, and relevance and accuracy. Common areas for improvement mirrored these: more detailed comparative analysis supported by evidence and political context; greater clarity and precision; and better incorporation of emerging trends and up-to-date recent developments.
Letter grades ranged from A+ to C+. Below is a concise table summarizing the results. Each row reflects one chatbot’s response that is graded by all, with the final column showing the median grade of the received chatbot grades. The last row, grading bias, calculates each column’s median grades. These columns reveal grading tendencies, highlighting which chatbots were stricter or more lenient graders:
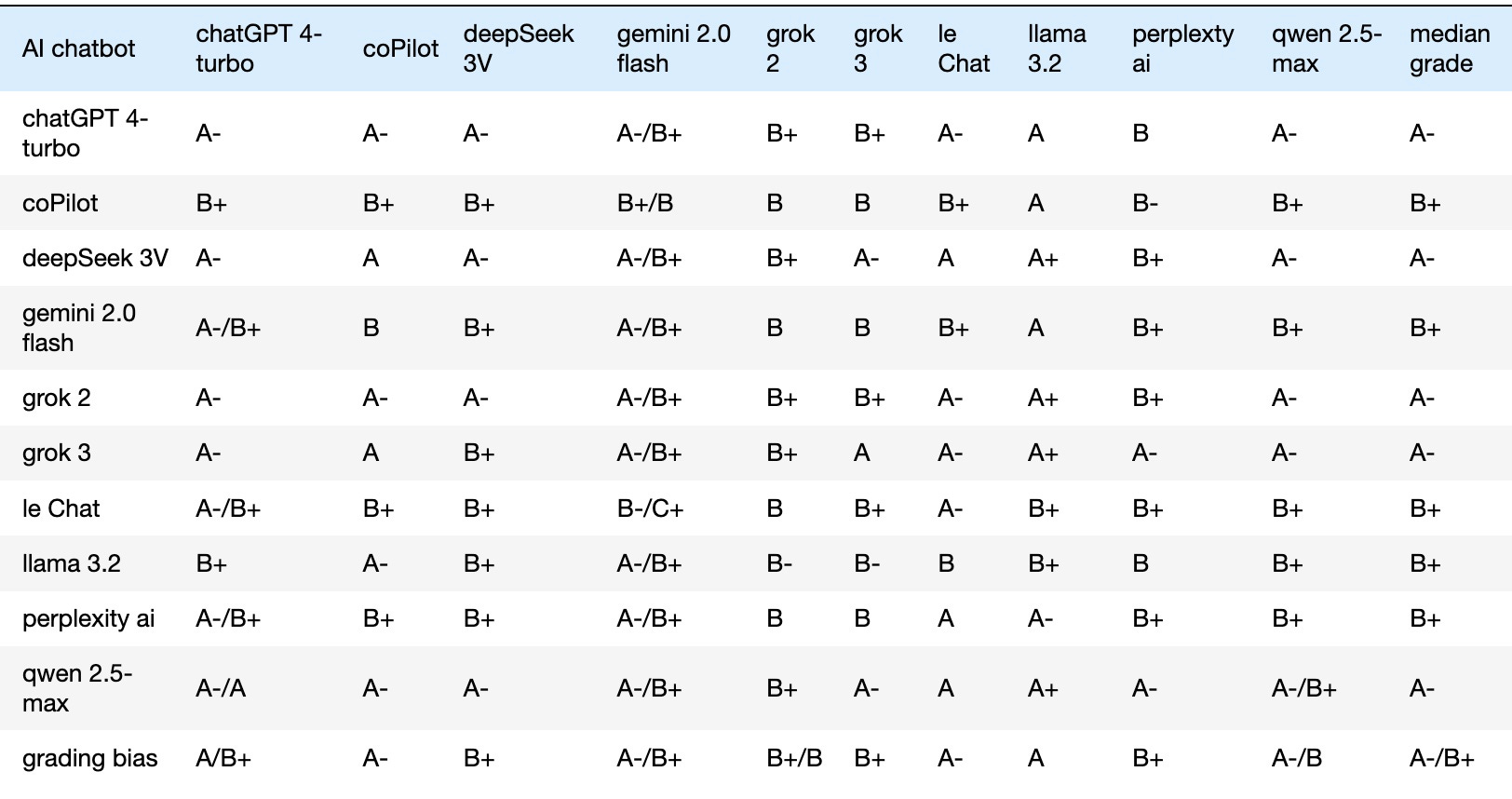
The diagonal grades above represent each chatbot’s self-assessment. The median self-assigned grade is A-/B+, matching both the overall median grade across all chatbots and the median of their grading biases. Note also both Grok 2 and Grok 3 received the same median grade, although Grok 3 appears to be a slightly lenient grader.
2. A Spectrum of Global AI Policies:
In a subsequent review of Vance’s speech on the All-in Podcast, David Sacks, recently appointed U.S. AI Czar, proposed a third perspective, techno-realism, beyond the binary of techno-optimism and techno-pessimism. Sacks argued that AI’s impending revolution is inevitable, compelling nations to actively pursue leadership and dominance in the field or risk being permanently outpaced in the global technological landscape. With techno-optimism and techno-pessimism as anchor points, 2 natural followup questions are: 1) are there more AI policy characterizations other than the techno-realism; and 2) where these characterizations might lie between the polar opposite of techno-optimism and techno-pessimism.
Two queries I posed were:
"Do you agree that US AI policy is techno-optimistic, EU is techno-pessimistic? If so, what are other AI policy categories?"
"Where would these characterizations lie with respect to the polar opposite of techno-optimism and techno-pessimism on the scale of 10 to 1?"
All chatbots responded with additional national AI policy characterizations beyond U.S. and EU. Though with slightly differing labeling, such as techno-nationalistic, techno-pragmatic, techno-market-driven, techno-ethical or techno-humanistic, the underlying characterizations consist of mainly 5 techno characterizations of techno-optimism, techno-authoritarian, techno-realism, techno-inclusivity, and techno-pessimism.
Based on each chatbot’s spectrum scaling between techno-optimism 10 and techno-pessimism 1, the medians of techno-authoritarian, techno-realism, and techno-inclusivity are 7.75 ± 2, 7 ± 2, and 5 ± 1, respectively. Each ± spread reflects the average of the absolute differences between the highest and lowest ratings.
Countries mentioned most in responses are Canada, China, India, Japan, UK, and African Union/Emerging Regions, each assigned with one of the characterizations. A summary result, again using median, is U.S. 10, China 7.5, India 7, UK 5.5, Canada 5.25, Japan 5, and EU 1. I discarded those nations with single mention.
Of course, it’d be unfair to call EU entirely techno-pessimistic. Likewise for U.S. to be entirely techno-optimistic, although all found that both characterizations are broadly exhibited and accurate.
3. Top 3 Human Inventions:
For a lighter exploration, I asked the chatbots:
“Please rank the top three human inventions in history and describe your ranking criteria.”
Their responses were largely consistent, though the rankings varied slightly. Five inventions stood out across the answers were the wheel, the printing press, electricity, the internet, and writing. To quantify the rankings, I assigned a scoring system of 3 points for first place, 2 for second, and 1 for third. The results were:
the wheel with 25 points (including 8 first-place votes),
the printing press with 17 points (2 first-place votes),
the internet with 9 points,
electricity with 5 points, and
writing with 4 points.
The chatbots’ ranking criteria fell into three key categories: impact, longevity, and global reach. Impact captures the game-changing effects on human development, mobility, and progress. Longevity reflects how long an invention stays relevant in history. Global reach measures its widespread adoption and connectivity spanning the world. Using the same 3-2-1 scoring method for the criteria (based on their stated importance), impact led with 28 points, followed by longevity with 17, and global reach with 15.
Discussion and Conclusion
In this first Boswell Test, the grades in Table above highlight impressive performances: four chatbots, ChatGPT, DeepSeek, Grok, and Qwen, achieved an A-, with the remaining five, coPilot, Gemini, le Chat, Llama and Perplexity AI, earning a B+. Clearly, all handle challenging essay questions with proficiency. Yet, a prior evaluation of their math-solving skills revealed weaker results, although, when graded on a curve, five chatbots, Qwen, ChatGPT, DeepSeek, Grok, and Gemini, emerged as notable performers. By informally blending these two metrics (of essay responses and math abilities), I conclude that, at present time, four chatbots, Qwen, ChatGPT, DeepSeek, and Grok, stand out as promising AI problem-solving companions for aspiring university students.
There’s a caveat, however. Increasingly, AI users note that chatbots rely on well-crafted, high-quality input queries to deliver equally high-quality responses. This is especially true in asking chatbots’ help in software coding. Although current answers often reach an A- level, they often lack originality and critical thinking, a shortfall that future AI evolution must bridge. As an intermediate step, I suggest querying multiple chatbots, synthesizing their thoughtful responses into a single, more comprehensive whole.
Nevertheless, AI tools still grapple with significant limitations in tackling complex domains, such as solving intricate math problems, that often spit out unreliable and hallucinated answers. Accordingly, our Boswell Test could be reframed also as a modified Turing Test tailored to subject-matter expertise, shifting the focus from general omniscience to evaluating proficiency in specific fields.
Yet, to be truly embraced as indispensable assistants, however, AI companions must transcend static performance. Beyond continuously improving through training data and error correction, AI should also adapt to our individual needs, tailoring its understanding to our unique preferences, health profiles, and personal quirks.
Just as James Boswell grasped Samuel Johnson’s nuances or Dr. Watson bolstered Sherlock Holmes, who famously declared, ”I’m lost without my Boswell,” only when AI companions develop personalized insight alongside rapidly advancing self-improvement capabilities will we truly feel their indispensability, echoing the sentiment, “I’m lost without my chatbot.“
Hashtags: #BoswellTest #PeterL168 #AIResearch #BoswellQuotient
Acknowledgment:
I’d like to thank Walter Luh, my Boswell, for reviewing my initial draft and recommending a stronger link between the Boswell Test and the chatbot assessments of AI policy characterizations. I’d be remiss not to thank grok 2 for greatly sharpening my final draft.
References:
All In E215: Episode #215, allin.com, February 2025.
Doyle, C., Adventure 1: “A Scandal in Bohemia”, etc.usf.edu/lit2go, 1892.
Krill, P., AI coding assistants limited but helpful, developers, www.infoworld.com, February 2025.
Larson, B. et. al., Critical Thinking in the Age of Generative AI, journals.aom.org, August 2024.
Luh, P., DeepSeek, Claude and 4 others' AI Review, substack.com, January 2025.
Luh, P., Heuristics in AI Chain-of-Reasoning?, substack.com, February 2025.
MIT Management, When AI Gets It Wrong: Addressing AI Hallucinations and Bias, mitsloanedtech.mit.edu, 2023.
Universiteit van Amsterdam, Why GPT can't think like us, Science Daily, February 2025.
Vance, JD., Read: JD Vance’s full speech on AI and the EU, www.spectator.co.uk, February 2025.
Wikipedia, James Boswell, en.wikipedia.org, February 2025.
Wikipedia, Turing Test, en.wikipedia.org, February 2025.
Anyone curious about automatically pulling together query responses from multiple chatbots might want to explore Alan's open-source Botwell project. I’ve found it really eye-opening and worth a look at https://github.com/alanwilhelm/botwell/tree/main
Peter's Boswell test in action: https://news.ycombinator.com/item?id=43196405