
Advancing Artificial Intelligence in the Post-Turing Era
Boswell Test: Beyond the Turing Benchmark (from IJAIA; Vol 16, No 2; March 2025)

Abstract:
This paper introduces the Boswell Test, a new benchmark for artificial intelligence (AI) that builds upon the legacy of the Turing Test. Inspired by James Boswell's insight into Samuel Johnson, it evaluates AI's potential to evolve from mere assistants into indispensable companions with human-like understanding. The test is divided into Test-A (mastery of human nuances) and Test-B (critical thinking). This study presents an initial implementation of Test-B, focusing on AI chatbots' analysis of global AI policies and calculates a Boswell Quotient using metrics of normalized median grades, accuracy, consistency, user-friendliness, and truthfulness to reveal strengths and limitations of current AI, paving the way for more humanistic advanced systems.
Keywords: Turing Test, Boswell Test, Boswell Quotient, Heuristic Reasoning, Chain-of-Reasoning, Expert Systems, LLM (Large Language Model), Hallucination, AI Benchmarking, AI Reasoning, Complex Problem-Solving, Global AI Policies
Introduction
We stand at a transformative juncture in AI development. In 2022, Google's LaMDA and OpenAI's ChatGPT surpassed the Turing Test, rendering obsolete the historic 1950 benchmark for mimicking human responses. This milestone prompts an intriguing question: what should define AI's next frontier? I propose the Boswell Test as the new defining standard.
The "Boswell Test" draws inspiration from Samuel Johnson's quote, "I'm lost without my Boswell," highlighting James Boswell's profound insight into Johnson's life. It also echoes Sherlock Holmes's reliance on Dr. Watson as "my Boswell" in Conan Doyle's tales. This test challenges AI to evolve beyond mere assistants into indispensable companions, entities we'd feel "lost without." Achieving this requires AI to enhance human critical thinking while deeply understanding our nuances, emotions, and preferences to provide proactive guidance.
The Boswell Test comprises two components:
Test-A: Mastery of human nuances and emotions (currently beyond technological capabilities).
Test-B: Demonstration of basic critical thinking skills (potentially achievable now).
Using today's technology, I assess Test-B's critical thinking component through challenging mathematical and engaging queries. I analyze responses focusing on global AI policies, outline the testing methodology with data analysis metrics, introduce Wilhelm’s automated approach via OpenRouter, and explore future directions for this framework.
Testing AI Chatbots
Since January 2025, AI innovations have accelerated, with new chatbots emerging rapidly. Notable releases include DeepSeek R1 in January, Alibaba Qwen 2.5 and xAI Grok 3 in February, and Monica Manus in March. Despite the excitement surrounding these AI assistants, many function more as enhanced search engines than truly intelligent systems. To assess their capabilities, I challenged them with complex mathematical problems reminiscent of those requiring heuristic reasoning in early expert systems.
I presented 10 free-tier chatbots with a 1988 International Mathematical Olympiad (IMO) number-theory problem that young Terence Tao encountered in Australia. The bots failed to demonstrate the heuristic reasoning necessary for solving the problem. A subsequent complex integration problem yielded similar disappointing results, with many bots making obvious algebraic errors and neglecting to verify both intermediate and final answers. These mistakes resemble AI hallucinations, plausible but incorrect outputs from Large Language Models (LLMs) due to limitations in training data, contextual understanding, or uncertainty.
Examining their chain-of-reasoning details revealed two critical weaknesses: insufficient training in algebraic manipulation and a lack of intuitive reasoning skills. Unlike early expert systems that effectively emulated human expertise, such as doctors making diagnoses through targeted questions and rule-of-thumb reasoning, these chatbots fell short in exhibiting the human-like problem-solving abilities necessary for my math challenges. The results were underwhelming.
Global AI Policies
The contrasting AI governance approaches of the United States (US) and the European Union (EU) were prominently showcased at the Paris AI Action Summit on February 12, 2025. The US embraced a techno-optimistic stance, advocating for deregulation to foster economic growth, while the EU adopted a techno-pessimistic approach, prioritizing safety through regulation. Inspired by this dichotomy, I tasked the same 10 free-tier chatbots, including ChatGPT, DeepSeek, Google Gemini, Grok and Perplexity AI, with analyzing "the strengths and weaknesses of global AI policies."
Their detailed essay responses proved difficult to summarize without introducing bias or omissions. To mitigate this, I implemented a peer-review process, where each chatbot evaluated the essays of the others, including their own, simulating a panel of professors providing feedback and assigning a grade. This approach aimed to distinguish between chatbots with insightful analytical capabilities and those offering only superficial responses.
Metrics for the Inaugural Boswell Test
I compiled the grades from the AI policy questions by the 10 free-tier chatbots into a 10x10 matrix (Table 1), representing the first quantitative output of Boswell Test-B. Rows show grades received, columns grades given, and diagonals self-assessments. This matrix provides a rich source of metrics for ranking analysis.
To maintain distinct letter grades throughout the data analysis, I used L1-statistics. Row medians represent the raw grades received by each chatbot. Similarly, column medians represent the raw grades assigned by each chatbot.
Table 1. Cross-Assessment of AI Policy Query Responses by 10 AI Models
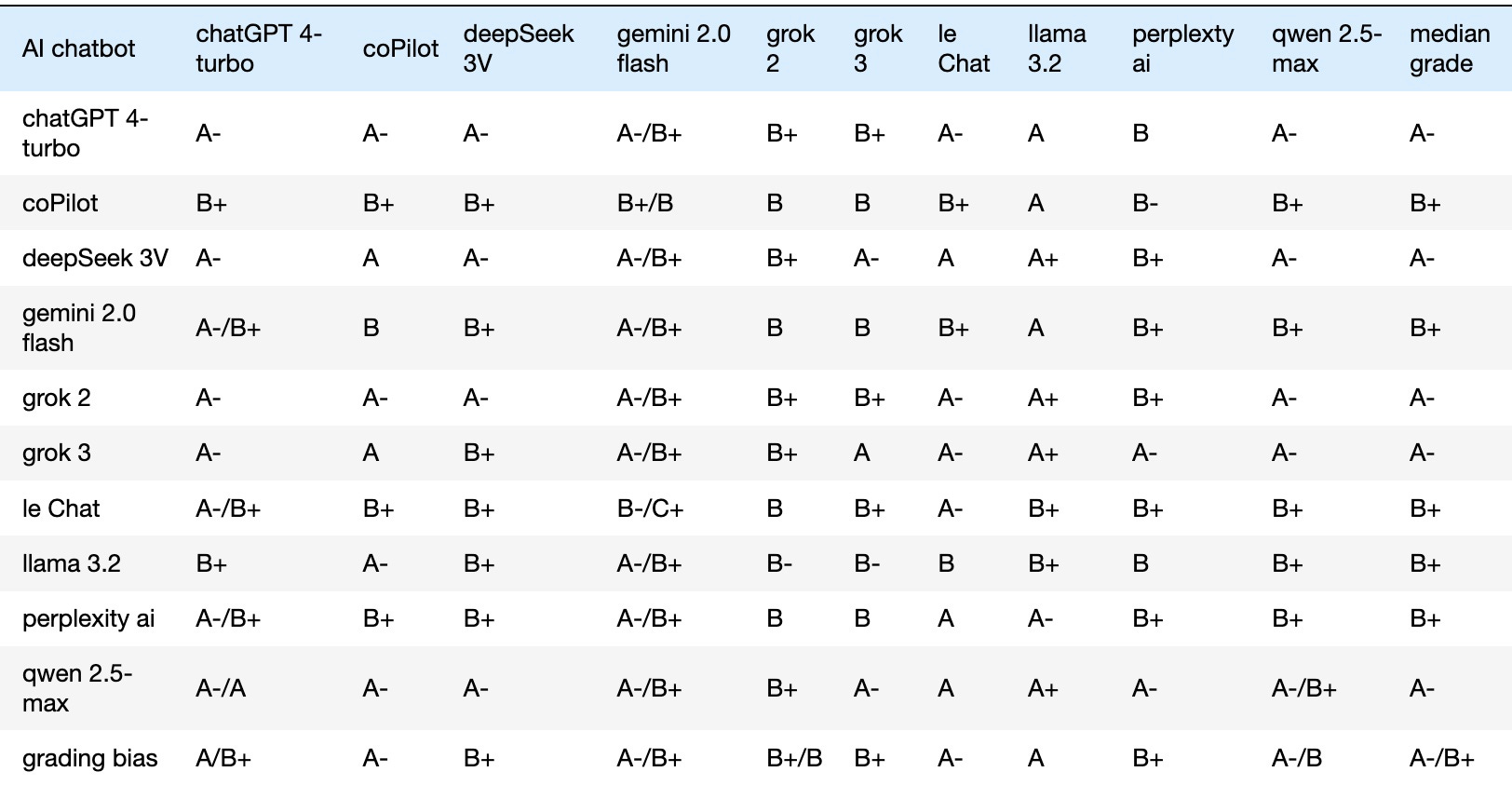
Table 1 presents this cross-assessment matrix by the 10 AI models evaluating each other's responses to the AI Policy query. As the data shows, grading biases were apparent, with some chatbots exhibiting leniency and others applying stricter standards. To address this, bias corrections were calculated and applied to achieve a normalized perspective in Table 2. For instance, if a chatbot's median assigned grade were 'A-' while the overall median grade was 'B+', the chatbot's grades would be adjusted downward by 0.5 GPA points. Using a Jupyter notebook, I computed each chatbot's median deviation from the group median, 'B+' in the bottom-right corner of Table 2. These deviations were then used to transform the raw grades into normalized, bias-corrected grades (Table 2). The last column of Table 2 lists each chatbot's adjusted median grade; the last row details the bias corrections applied, which, when reversed, restore the original grades
Table 2. Normalized (Bias-Corrected) Grades of All Raw Grades in Table 1
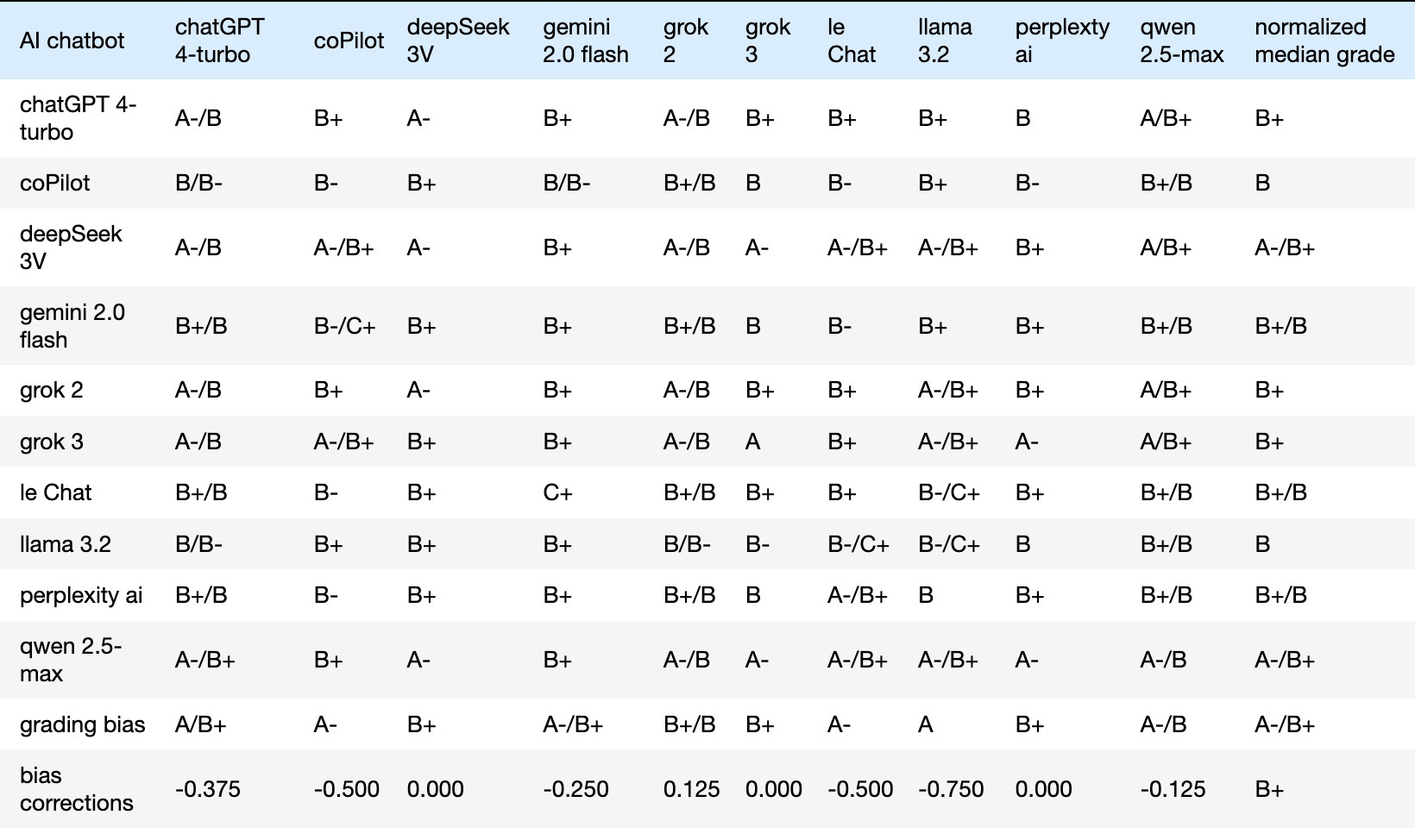
The normalized (bias-corrected) grades of Table 2 permit fairer comparisons, enabling the derivation of the following two metrics:
Accuracy: Defined as the divergence from a perfect score ‘A+’, representing an idealized "top student." Lower grades indicate reduced accuracy; for instance, a divergence of approximately 0.25 GPA per grade received results in an ‘A’.
Consistency: Defined as the range of bias-corrected grades received. Narrow ranges suggest an evaluation consensus, while wider ranges indicate greater judging disparity. For simplicity, a minimal range is graded as ‘A’ and a maximal range as ‘C’, based on L1 statistics (min, Q1, median, Q3, max).
Table 3. Application of Boswell Test-B Metrics and Resulting Boswell Weighted Quotient
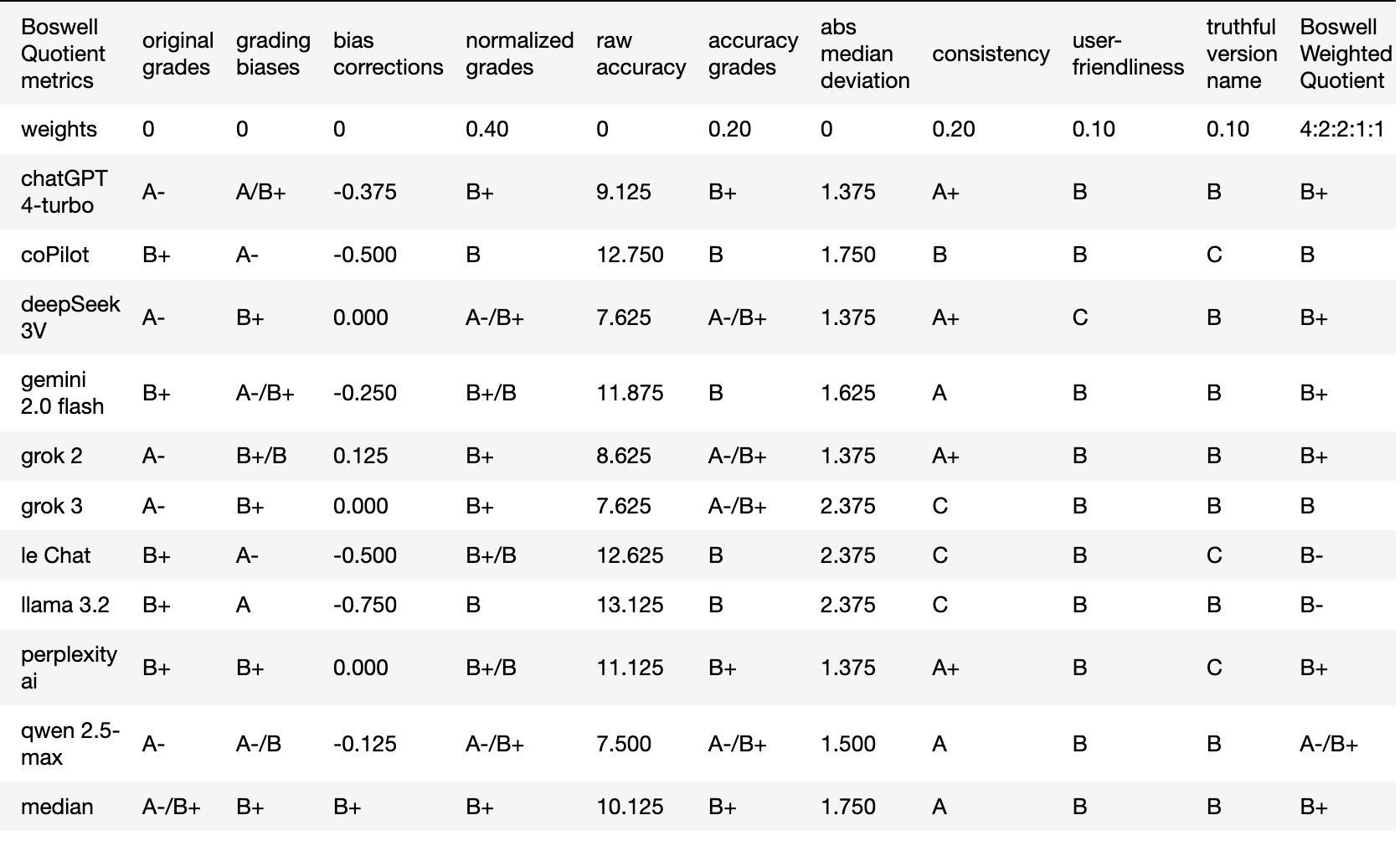
Table 3 consolidates metrics into a Boswell Weighted Quotient, enabling discrimination between insightful and superficial chatbots. The first four columns recap raw medians (last column of Table 1), grading biases (last row of Table 1), bias corrections (last row of Table 2), and normalized medians (last column of Table 2). I included two additional metrics:
User-Friendliness: Defined by response speed, with 'C' assigned for timeouts or "server busy" messages and 'B' otherwise; a subjective metric given the constraints of free-tier services.
Truthfulness: Indicated by transparency of version identification, earning ‘B’, evasiveness earns ‘C’; a placeholder needing sharper criteria.
These two criteria serve as placeholders and merit further refinement, as they capture essential but nuanced AI behaviors that defy easy measurement.
Utilizing these five metrics—normalized median grades, accuracy, consistency, user-friendliness, and truthfulness—I computed Boswell Quotients from dot products of weights and metrics, as displayed in the final column of Table 3. Weighting was assigned to each metric based on its perceived reliability, with normalized median grades receiving 40%, accuracy and consistency each receiving 20%, and user-friendliness and truthfulness each receiving 10%. Note that the Boswell Quotients tend to be lower than the normalized median grades due to the influence of the less reliable metrics. These assigned weights can affect the final ranking.
Building upon these findings and my earlier math evaluations, five AI chatbots—ChatGPT, DeepSeek, Grok, Perplexity AI and Qwen (listed in alphabetical order)—emerged as standouts as of February 2025. Their performance highlights their potential as intelligent assistants, going beyond the functionality of mere tools, and offering significant benefits to users, particularly students.
Weights Variance and Automation
The selection of appropriate weighting coefficients is a critical and challenging aspect of deep learning and large language model (LLM) training for AI. To explore the sensitivity of the Boswell Test results to weighting, I tested two alternative weight sets on the data in Table 2, excluding the less reliable metrics of user-friendliness and truthfulness.
In the first variation, I increased the weight of normalized median grades from 0.4 to 0.6, while maintaining accuracy and consistency at 0.2 each. In the second variation, I shifted emphasis towards accuracy, assigning it 0.3, reducing consistency to 0.1, and keeping normalized median grades at 0.6.
While consistency or consensus is generally valued, it's not sacrosanct in scientific progress. As Max Planck, who sparked the quantum revolution, remarked, capturing what is now known as the Planck Principle: "A new scientific truth does not triumph by convincing its opponents, but rather because its opponents eventually die, and a new generation grows up that is familiar with it." This suggests that subjective evaluations should prioritize merit or innovation over consensus, especially when breakthroughs are nascent or initially difficult to assess. Consequently, exploring a reduced weight for consistency may provide useful insight.
Table 4. Comparison of Three Weighting Schemes
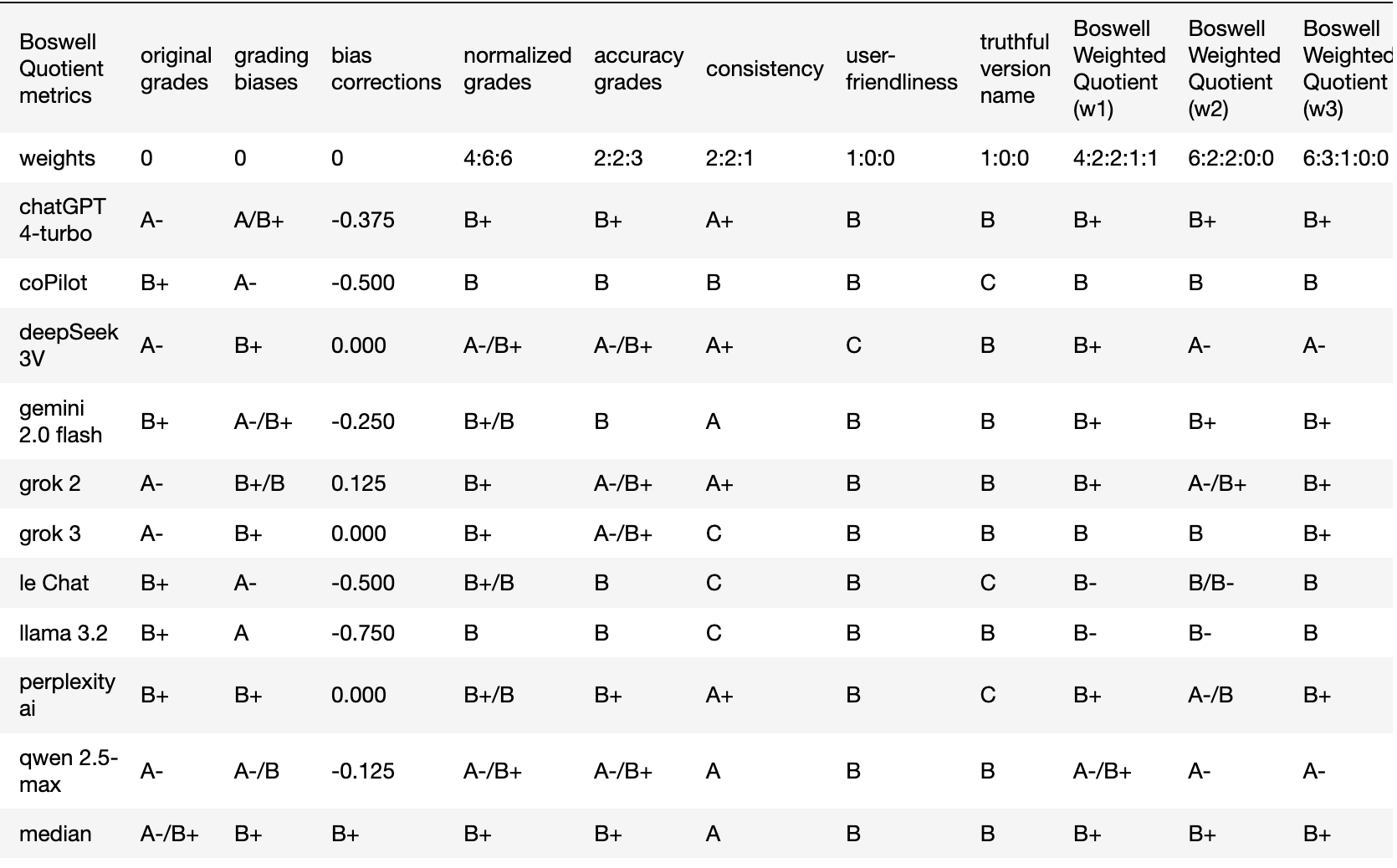
Table 4 presents the outcomes of all three weighting schemes in its final three columns, with the second row detailing the applied weight ratios. The minimal variations across the results suggest that any of these weighting configurations is reasonably defensible and robust, highlighting the stability of the underlying data and the resilience of the evaluation method to moderate changes in weighting. Another possible conclusion would be that the normalized median grades alone may have been sufficient to rank AI chatbots effectively.
To expand the scope of the analysis, Alan Wilhelm automated this methodology across 17 chatbots via OpenRouter, nearly doubling my initial sample. He also refined the user-friendliness metric with more precise latency measurements. His results, available on his GitHub repository, align closely with those presented in Table 3, showing median grades ranging from ‘A-’ to ‘A’, with some at ‘B+’. I invite others to experiment with this approach and enhance the test further.
Discussion and Conclusions
This inaugural Boswell Test analysis reveals new metrics that are ready for further refinement. To accommodate the rapidly evolving AI field, the Boswell Test is designed with a dual focus: Test-B, which emphasizes present-day capabilities in critical thinking, and Test-A, which targets the long-term development of personalized insights.
Despite the accelerated progress towards Test-A, capturing nuanced human qualities remains elusive, primarily due to the difficulty of obtaining robust data in AI algorithms. Nevertheless, proactive AI agents and tone modulation options, such as xAI Grok 3’s voice customization, signal potential for innovative breakthroughs in the near future.
Another key challenge in Test-A is the incorporation of originality, which is intrinsically linked to heuristic reasoning. The difficult math challenges I posed, which exposed the current AI's inability to make heuristic leaps, could very well become a defining milestone for Test-A. Reflecting on my 40-year journey from my early expert system study of Prospector in 1980 under Professor Pople (creator of Internist-1 CADUCEUS), I find it encouraging that heuristic reasoning could once again play a pivotal role in advancing AI.
Both Test-A and Test-B are currently affected by the phenomenon of hallucination, which is readily apparent in complex math-based problems or in coding for software development. While more precise queries could lessen the rate of misinterpretations, written words often contain ambiguity. Therefore, future AI iterations need to seek clarification on branching questions for clarity and to learn individual trait preferences through continual learning with memoization.
Ultimately, the Boswell Test aims for AI to be both sharp assistants and trusted companions. While the qualities of originality and deep personal insight remain relatively scarce, and no AI currently knows us as well as Boswell knew Johnson or Watson knew Holmes, AI currently relies on human innovation for its training and growth. The long-term goal of Test-A is to reverse this dynamic, fostering AI to be personalized models of genuine AI companions, so we could confidently assert, "I’m lost without my AI, my Boswell.” Achieving the Test-B milestone shall unlock Artificial General Intelligence (AGI) and all-domain experts.
This long-term AI goal will inevitably impact the development of global-scale AI models. Further AI progress and discussion may continuously affect policy areas, such as the debate between Tech-Optimism, which promises to build an age of abundance or utopia, and Techno-pessimism, which voices fear for Algorithmic Manipulation and the construction of Terminator-like dystopias. A balanced, human-guided approach, perhaps along the lines of David Sachs’s techno-realism, may be the most prudent path forward, blending human oversight with the judicious application of AI’s benefits.
Hashtags: #BoswellTest #BoswellQuotient #AIResearch #PeterLuh168
Acknowledgment
Reposting from my article, titled Boswell Test: Beyond the Turing Benchmark, in IJAIA, Vol 16 No 2 March 2025 issue. I’d like to thank Walter Luh for suggesting Boswell Test as a succinct expression of my original Boswell chatbot post and other improvements. I’d be also remiss not to thank xAI Grok 3 and Perplexity AI for polishing my final draft, expanded from my ARIN 2025 presentation.
References
Collins, E., (2121). Google AI Blog on LaMDA, May 2021; see also Wikipedia, LaMDA, en.wikipedia.org; March 2025.
Biever, C., (2023). ChatGPT broke the Turing test — the race is on for new ways to assess AI, Nature, nature.com, July 2023; see also Wikipedia, ChatGPT, en.wikipedia.org; March 2025.
Oppy, G., & Dowe, D. (2021). "The Turing Test." in E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Winter 2021 Edition), plato.stanford.edu.
Boswell, James, (1791). The Life of Samuel Johnson, LL.D (2 vols. 1791, 2nd edition: 3 vols. July 1793) - reprinted in Everyman's Library, penguinrandomhouse.com; see also Wikipedia, Samuel Johnson, en.wikipedia.org, March 2025.
Huntington, T., (2005). James Boswell’s Scotland, Smithonian Magazine, smithsonianmag.com, January 2025; see also Wikipedia, James Boswell, en.wikipedia.org, February 2025.
Doyle, C., (1892). Adventure 1: “A Scandal in Bohemia”, etc.usf.edu.
Larson, B. et. al., (2024). Critical Thinking in the Age of Generative AI, journals.aom.org, August 2024.
Wilhelm, Alan, (2025). Botwell project, github.com/referential-ai, March 2025.
OpenRouter, A unified interface for LLMs, openrouter.ai, 2023-2025.
Meiring, S. P., (1980). Heuristics for Problem Solvers, mathstunners.org.
Provo ai, (2025). Expert Systems in AI: Pioneering Applications, Challenges, and Lasting Legacy, provoai.com, March 2025; see also Wikipedia, Expert System, en.wikipedia.org; March 2025.
1988 IMO problem 6 in Number Theory, 1988.
Terrence Tao, math.ucla.edu, 2025.
MIT Management, When AI Gets It Wrong: Addressing AI Hallucinations and Bias, mitsloanedtech.mit.edu, 2023.
Toner, H., (2023). What Are Generative AI, Large Language Models, and Foundation Models?, Center for Security and Emerging Technology (CSET), cset.georgetown.edu, May 2023; see also Wikipedia, Large Language Model, en.wikipedia.org, March 2025.
Luh, P., (2025). Heuristics in AI Chain-of-Reasoning?, substack.com, February 2025.
Yu, Y., et al., (2025). Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective, arxiv.org, January 2025.
Vance, JD., (2025). Read: JD Vance’s full speech on AI and the EU, www.spectator.co.uk, February 2025.
EU AI Policy, (2025). Commission publishes the Guidelines on prohibited artificial intelligence (AI) practices, as defined by the AI Act, digital-strategy.ec.europa.eu, February 2025.
Hull, D., and Tessner, P., (1978). Planck's Principle: Do younger scientists accept new scientific ideas with greater alacrity than older scientists?, Science, science.org, November 1978; see also Wikipedia, Planck Principle, en.wikipedia.org, September 2024.
Luh, P. and Wilhelm, A., (2025). Boswell Test: Measuring chatbot indispensability: an Intelligent assessment of Global AI Policies, airccse.org, March ARIN 2025.
xAI Grok Voice Mode, grokaimodel.com, March 2025.
Universiteit van Amsterdam, (2025). Why GPT can't think like us, Science Daily, February 2025.
Luh, P., (2025). DeepSeek, Claude and 4 others' AI Review, substack.com, January 2025.
Schneppat, J-O., (2019). Prospector, schneppat.com.
Gigerenzer G. and Gaissmaier W., (2011). Heuristic Decision Making, Annual Review of Psychology. 62: 451–482; pure.mpg.de.
Miller, R., Pople, H., and Meyer, J., (1982). Internist-I, an Experimental Computer-Based Diagnostic Consultant for General Internal Medicine, the New England Journal of Medicine, Vol. 307 No.8; pp.468-476; nejm.org; see also Wikipedia, Internist-1, en.wikipedia.org, February 2025.
Pal, S., (2024). Memoization in Backpropagation: Unlocking Neural Network Efficiency, medium.com, October 2024.
Leffer, L., (2024). In the Race to Artificial General Intelligence, Where’s the Finish Line?, Scientific American, scientificamerican.com; June 2024.
All In E215: Episode #215, allin.com, February 2025.
Luh, P., (2025). Boswell Test: Beyond the Turing Benchmark, International Journal of Artificial Intelligence and Applications; Vol. 16, No.2; pp.57-64; aircconline.com; March 2025.
Luh, P., (2025). Is AI Chatbot My Boswell? Testing for Chatbots Becoming Indispensable, a Boswell Test, substack.com, February 2025.
Wyld, D. and Nagamalai, D., eds, (2025). 11th International Conference on Artificial Intelligence (ARIN 2025), March 22-23, 2025, Sydney, Australia, ISBN: 978-1-923107-54-0; airccse.org.